
Introduction to Cloud Native & Analysis Ready Data Formats¶
Instructors(s):¶
Tyson Lee Swetnam PhD  ,
Carlos Lizárraga-Celaya PhD
,
Carlos Lizárraga-Celaya PhD
About¶
This website follows the FAIR and CARE data principles and hopes to help further open science.
Agenda¶
| Lessons | Estimated Time to Complete | Link |
|---|---|---|
| Introduction to Cloud Native Data Types | 15 minutes | presentation |
| Hands on with GeoJSON | 30 minutes | GeoJSON.io |
| Hands on with Cloud Optimized GeoTIFF | 30 minutes | cogeo.org |
| Break | 10 minutes | |
| Hands on with XArray & Zarr | 30 minutes | Xarray, Zarr |
| Hands on with Cloud Optimized Point Clouds | 30 minutes | COPC |
| Hands on with Spatio-Temporal Asset Catalogs | 30 minutes | STAC |
| Summary and Conclusion | 5 minutes |
Pre-requisites¶
- a laptop with an active wifi connection
helpful but not required¶
- a basic understanding of the Command Line Interface (UNIX)
- a basic understanding of Python3
Why "cloud native"?¶
There is a shift happening in the way we use Earth Observation System data to do research and management. Cloud data storage technologies have advanced at such a pace that we can now find and explore massive amounts of data via our web browser. At the same time online platforms with specialized software and hardware offer general data science and machine learning tools to explore these online datasets.
With these advances it is easier to foster collaborations, promote data-driven discovery, drive scientific innovation, increase transparency and improve reproducibility.

Many of us have been participants in "sneaker net" and "mail order" data delivery ordering and managing data transfers over physical media. These data are then processed on our workstations and laptop computers and ultimately put on external hard drives or uploaded back to national data services. GIS data have changed hands for years over conventional internet protocols (https://, ftp://, and newer s3://), where datasets are preferentially DOWNLOADED to our local compute resources and worked on.
"Cloud Native" means you are no longer looking to download all of your GIS data. Instead, we send our "code" and our execution tasks to the "Cloud" where the data are processed, and serviced over a variety of commercial cloud providers who are already hosting these large geospatial datasets (often free of cost to us). Results can be viewed in the browser, or streamed in reduced formats back to our local computers.

Cloud-native and "Analysis Ready Data" formats allow us to work with large datasets on the cloud easily and rather painlessly.
Open Architectures¶
The new approach to data sharing, focused on object storage rather than file downloads. This cloud platform approach is scalable and instead of moving data to processing systems near users as is the tradition, brings processing, computing, analytics and visualization to data – so called data proximate workbench capabilities, sometimes also referred to as server-side processing.
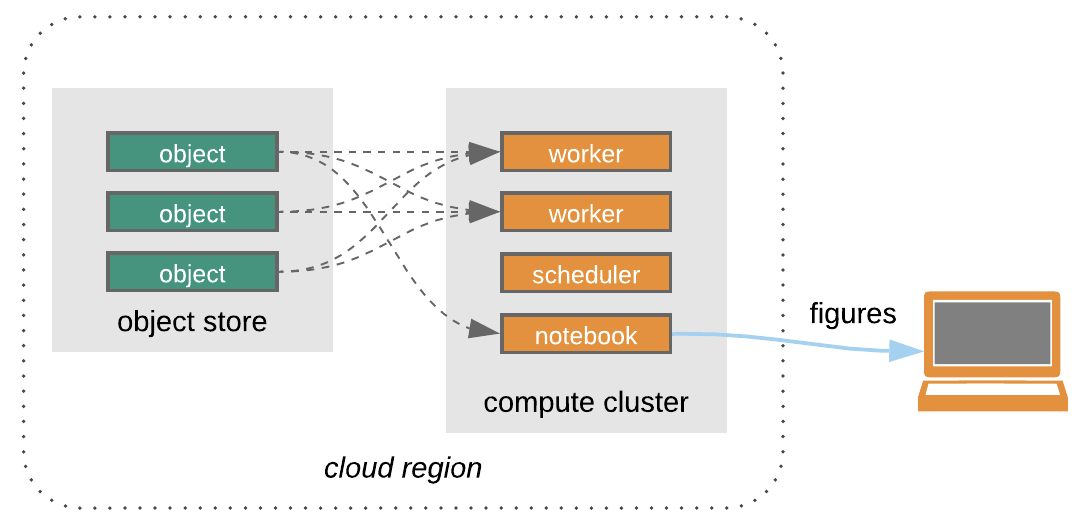
(Open Architecture for scalable cloud-based data analytics. From Abernathey, Ryan (2020): Data Access Modes in Science.)
Light reading¶
Gentemann, C. L., et al. (2021). “Science Storms the Cloud”. AGU Advances, 2, e2020AV000354. https://doi.org/10.1029/2020AV000354
Abernathey, R. P. et al. (2021) "Cloud-Native Repositories for Big Scientific Data," in Computing in Science & Engineering, vol. 23, no. 2, pp. 26-35, 1 March-April 2021, https://doi.org/10.1109/MCSE.2021.3059437